I wanted to try vocoding using previously recorded sounds. First, I recorded a speech that Itō delivered in the United States in 1872 to use as an experimental source. The speech is as follows:
“In acknowledging the generous hospitality of your welcome, we feel from the depths of grateful hearts the honor conferred upon us. His Majesty our Emperor having the noble desire to increase our prosperity and extend our commercial relations with friendly powers, has sent us to your country on this important mission. Our people require much that you can furnish us, and we shall look largely to our nearest enlightened neighbors for those supplies of which we stand in need. The object of our mission is to inspect and examine into the various mechanic arts and sciences which have assisted your country in gaining the present high position she occupies before the world. We come to study your strength, that, by adopting wisely your better ways, we may hereafter be stronger ourselves. We shall require your mechanics to teach our people many things, and the more our intercourse increases the more we shall call upon you. We shall labor to place Japan on an equal basis, in the future, with those countries whose modern civilization is now our guide. The friendly intercourse of commerce will necessarily draw us closer together, and the State of California will be among the first to receive such benefits as must necessarily flow from more intimate relations. Notwithstanding the various customs, manners, and institutions of the different nations, we are all members of one large human family, and under the control of the same Almighty Being, and we believe it is our common destiny to reach a yet nobler civilization than the world has yet seen. Now, I am sure that you are the advocates of these principles; and these hospitalities, so generously offered, we receive as a compliment to our nation, and as the public expression of these magnanimous sentiments. With thankful hearts, therefore, let us drink to a closer friendship between our countries—one whose benefits shall be mutual and lasting.”
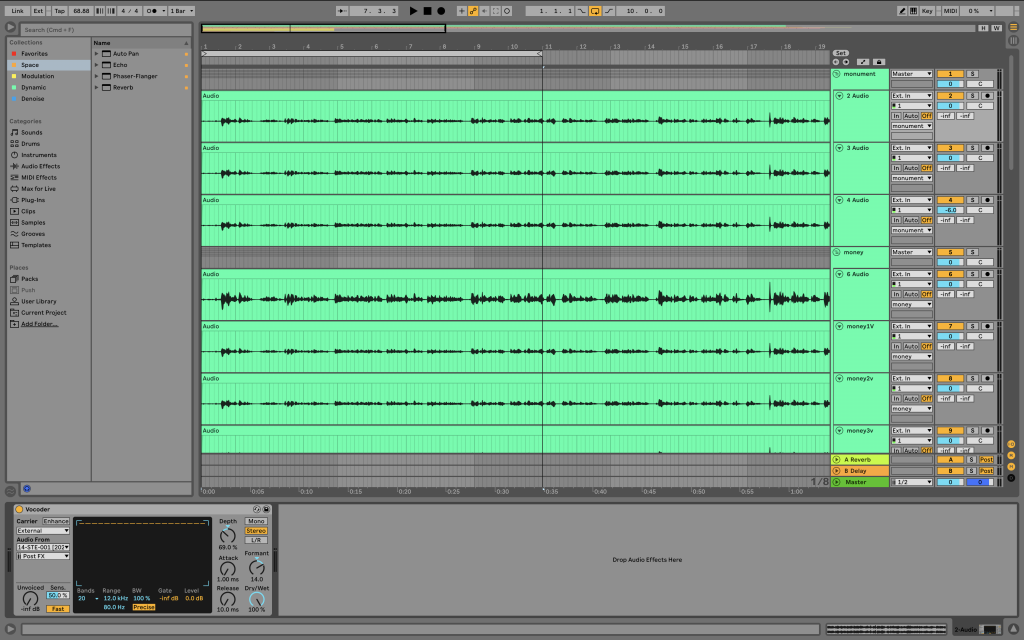
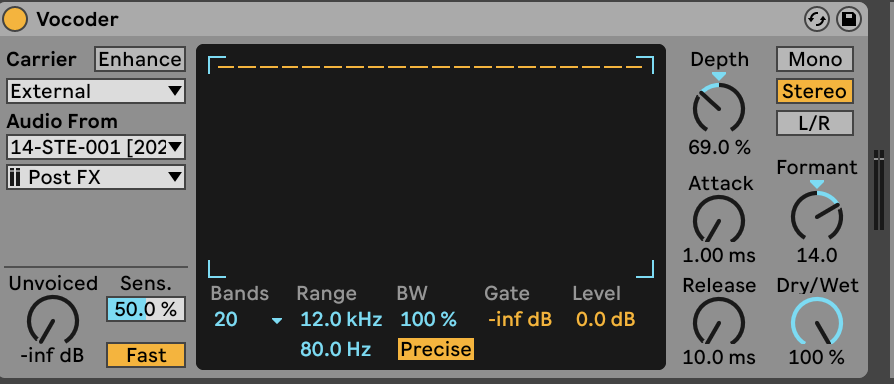
After recording the speech, I applied vocoding effects to the sounds of tombstones and banknotes that I had previously recorded. While vocoding, I focused on three parameters of the effect: Depth, Formant, and Release.
- Depth: The lower the setting, the more sensitive the effect is to the recorded file; the higher the setting, the less sensitive it becomes. For sounds that interfere with tone formation, such as low-frequency, repetitive sounds, I increased the Depth to reduce their occurrence. In contrast, for sounds that need to be continuously sustained, such as scraping sounds, I set the Depth lower.
- Formant: This controls whether the effect emphasizes lower or higher frequencies. I adjusted this parameter depending on the characteristics of the sound I used as the carrier.
- Release: This determines how long a sound takes to fade out. A higher Release setting results in less clarity in the original speech, while a lower setting preserves the speech’s nuance more effectively. Based on these characteristics, I carefully adjusted each vocoding effect parameter.
However, the original recordings contained intermittent sounds, which hindered effective vocoding. To address this, I classified and rearranged certain sounds into a continuous sequence, then applied vocoding separately to multiple audio sections.
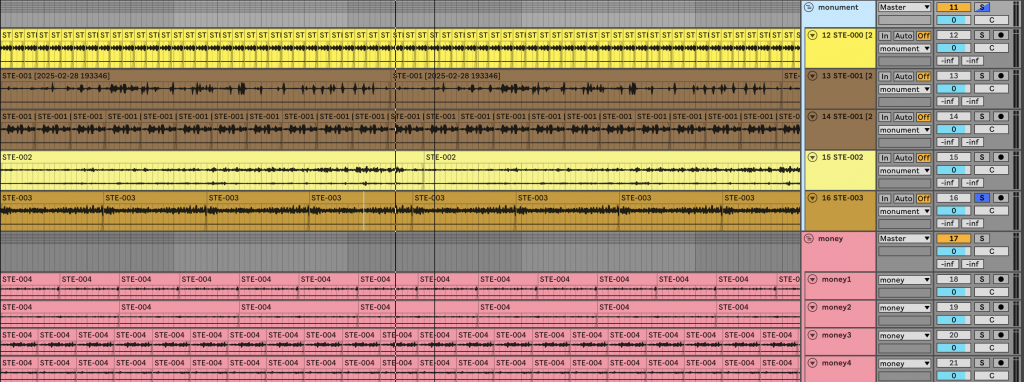
Upon reviewing the results, the sound felt somewhat lacking, and it did not quite resemble human speech. To better understand the cause of this, I plan to use a recording of someone portraying Itō Hirobumi speaking in Japanese and apply the same effect to analyze what went wrong.